
On vector databases
A brief overview of the space, interesting startups, and future adoption

Some context
A vector database indexes and stores vector embeddings for fast retrieval and similarity search, with capabilities like CRUD operations, metadata filtering, and horizontal scaling. Vector Databases have recently become a popular focus of development and investment because of its capability to extend large language models with long-term memory. Users or businesses will start with a general purpose foundation model like OpenAI’s GPT-4 or Google’s LaMDA. They will then connect their own data from a vector database. When a user submits a prompt, a program can query relevant documents using a vector database and then update the context for the model, which will customize the final output returned to the user. This mechanism can also support retrieval of historical data to support AI long-term memory. I found this concept best illustrated in Weaviate's graphic below:

Use cases
Foundation models - This technology has already been adopted by consumers for productivity boosts in both personal and professional usage. It is probable that businesses will follow suit in the near future by deploying foundation model tools to supercharge employee efficiency across many verticals including: finance, sales, customer success, and more. However, organizations need to tailor a base foundation model to embed their proprietary organizational data - the vector database will be important in facilitating this architecture as shown in the diagram above.
Few-shot learning - Few-shot learning trains a model to recognize new concepts, objects, or patterns with only a few examples. LLMs appear to perform few-shot learning well across different bespoke contexts. Vector databases can support the few-shot learning by storing representations of concepts or objects in vector format, and performing similarity searches to retrieve the most conceptually similar vectors (and related information) to a given desired query vector converted from a user prompt.
Model Management - Business foundation models will run into the same sorts of organizational privacy and security considerations that concern data. ML infrastructure will need to be developed that ensures secure and authenticated access to proprietary foundation models among intra-organizational departments or even across different organizations. Vector database access management using traditional concepts like roles and namespaces can potentially be important in the development of this space.
Promising startup opportunities
Qdrant - Qdrant is an open-source vector similarity search engine and vector database that is supported by a primarily Germany based team. Qdrant is a popular open-source alternative to Pinecone. They released a fully managed service, which their open-source users were keen on considering; their free cloud service trial offers a permanent 1GB trial cluster. They have shown strong download activity in the past few months. A potential concern surrounds their scalability as the ANN Benchmarks (shown below) place them in the lower-middle tier performers for recall-queries per second tradeoff. They recently raised a $9.5M seed round at $50M post, so this presents an early-stage investment opportunity.
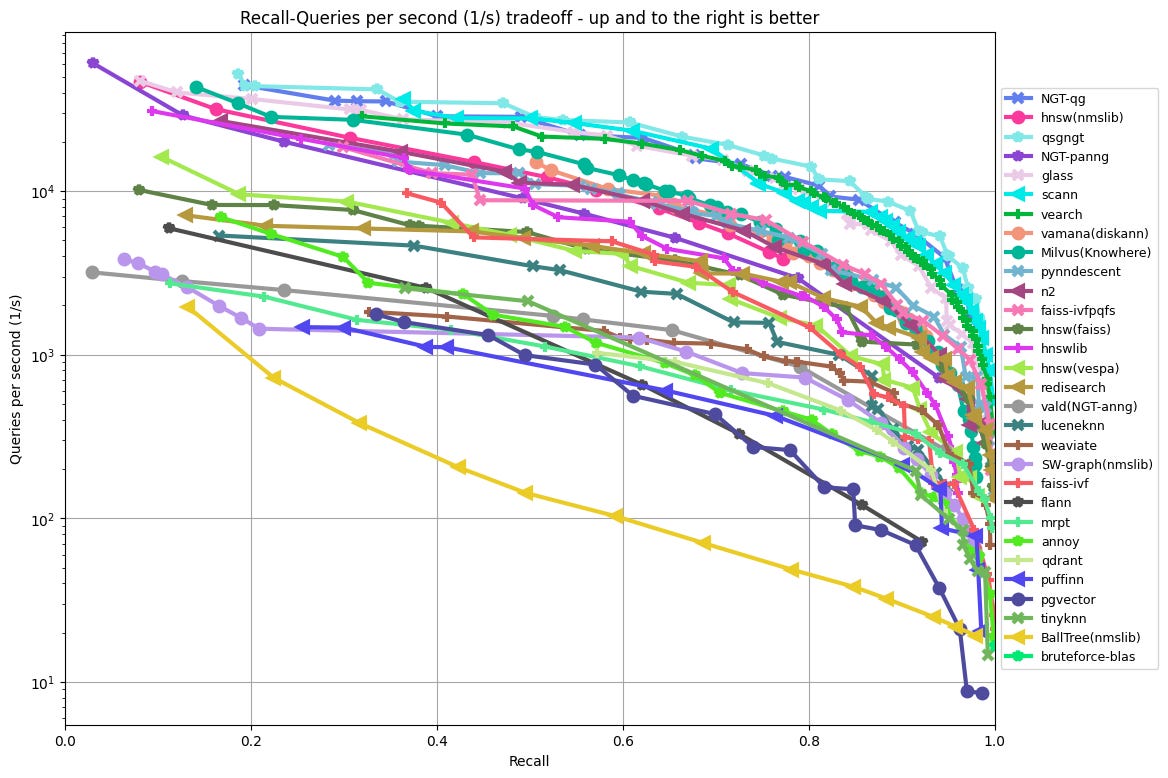
This plot from ANN Benchmark shows Recall (the fraction of true nearest neighbors found, on average over all queries) against Queries per second.
Chroma - Chroma is an open-source embedding database that supports the building of LLM apps by plugging in bespoke knowledge into base LLM. Chroma is very new, being founded in 2022 by a strong SF based team made up of a serial entrepreneur, research engineer, and software engineer. Developers find Chroma’s LangChain integration to be very easy to use out of the box. Their python client SDK has gained massive traction from double-digit daily downloads in February to now nearly 8K daily downloads. On 5/10/23 at GoogleIO, Chroma was publicly announced as a planned integration for Google’s PaLM and Firebase products. There are still no standard benchmarks available for Chroma’s recall/query performance; this leaves some developers with hesitancy regarding their production usage. They recently raised an $18 seed round led by Quiet Capital with prominent angel investors including Amjad Masad, Jack Altman, and Naval Ravikant. This presents a still early-stage opportunity.
Marqo - Marqo is an open-source, end-to-end, multimodal vector search engine that can be used to store and query unstructured data such as text, images, and code through a single easy-to-use API. The software includes input preprocessing, machine learning inference, and storage capabilities out of the box that can be scaled. The founders are Australia based and technically strong as a former Amazon software engineer and ML scientist. The team has also grown to 17 employees since being founded in 2022. They are differentiated with additional functionality to make vector search easier such as performing multi-modal and cross-modal search, and searching using an image. However, there are no standard benchmarks available for Marqo, so the scalability of the software is still a question. Additionally, while there has been slightly more python library download activity since February, it has generally not grown beyond 400 daily downloads. Marqo raised an undisclosed amount of seed funding from UK based Creator Fund in 2022. This also presents an early-stage opportunity.
Pinecone - Pinecone is one of the market leaders in fully managed vector databases and based in New York City. Their platform was built to deploy complex ML applications at scale with ease and serve as a “long-term memory for AI”. Pinecone’s success rides on its bet that most companies will be 1) dealing with larger scale data (>100M embeddings) 2) have strict performance requirements and 3) don’t want to manage their own vector databases. The downsides are that Pinecone is closed-source so it’s unverifiable what search engines they are using internally. Some sources state that their Exact KNN is powered by Faiss and ANN is powered by a proprietary algorithm. Additionally, their existing API set is limited with only basic operations provided. Their existing AI integrations are fewer than Zilliz. Additionally, their python package downloads have fallen off from its peak in mid-April this year. They are a well funded having recently raised an a16z led $100M Series B at $750 post. They are also generally favored by the developers for their community engagement and customer support.
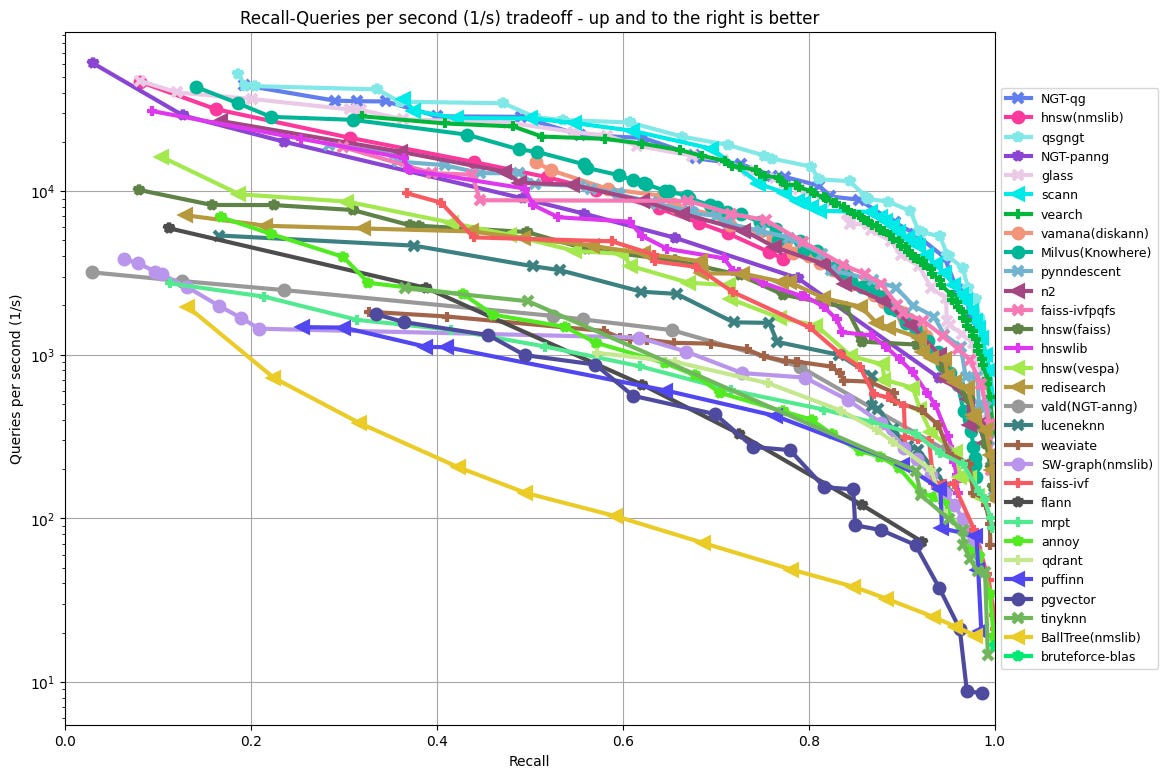
Weaviate - Weaviate is an open-source vector database that also offers a fully-managed cloud service. The development team is based in the Netherlands. They are developer friendly with strong documentation and an informative YouTube channel supporting their evangelism efforts. This has translated to strong user growth since February this year after they released their generative search module. They now have around 9K daily python client library downloads. However, their ANN Benchmark performance is at the lower-middle tier. They’ve raised a $50M Series B at $200M post led by Index.
Zilliz (Milvus) - Zilliz offers a fully managed vector database based on the popular and performant open-source software Milvus. Zilliz has one of the most comprehensive developer API and integrations with popular AI tools including OpenAI, HuggingFace, Cohere, PyTorch, Sentence Transformers, LlamaIndex, and LangChain. Their cloud deployment is seamless and flexible with a multi-cloud offering including AWS, Google Cloud, and Azure. Additionally, Milvus is amongst the top performers in recall-queries per second tradeoff, according to ANN Benchmarks. The Milvus python package also recently overtook Pinecone in daily downloads with around 20K. While Milvus may see rapid adoption amongst products and business infrastructure, Zilliz is Shanghai based so will certainly face headwinds as it tries to expand in the US. It has raised $72.5M to date from large investors such as Prosperity7.
Where do database incumbents stand?
I generally think that database incumbents (Elasticsearch, Redis, Postgres, etc.) will have opportunities to provide existing users/customers with vector database feature support through their own product extensions and developments. I think their customers that attempt (at least in the short term) in-house management of vector database integrated with their IT infrastructure will share some combination of these characteristics:
Cost sensitive
Tolerant of lower latency and smaller scale vector search operations
Apprehensive towards shifting company data off premise into the cloud
Product-led and has the competency to scale and manage their own internal vector database
If AI, LLM, and vector database usage continues to grow, I do anticipate that many non-software companies will run into performance bottlenecks when scaling their in-house solutions to production size and may look to eventually shift to fully-managed enterprise vector databases after failed internal attempts. Additionally, current incumbent extensions for embedded vector solutions are potentially still deficient.
Elasticsearch was first supported by an extension Elastiknn plugin that had bottom tier performance in the ANN Benchmarks. A disclaimer was even stated, “If you need high-throughput nearest neighbor search for periodic batch jobs, there are several faster and simpler methods. Ann-benchmarks is a good place to find them.” Elasticsearch added native vector support in version 7.10 released on 11/11/20 but I did not find relevant benchmark data.
Redis Enterprise seems to have included vector database functionality. However, open source Redis usage of vector storing and searching seems to require custom implementation that is non-trivial when compared to native vector databases.
Pgvector is Postgres’ open source vector similarity and search extension that is built on top of the Faiss library, which is a popular library for efficient similarity search of dense vectors. It is also easy to install and use. It has shown steady growth in daily python client downloads since February. However, its recall-queries per second tradeoff performance is amongst the worst in the ANN Benchmarks.
Bets on the future
I think that some product-led companies might decide to build and maintain their own vector database and search engine infrastructure. This might be done, for example, through rudimentary vector file/dataset storage in AWS S3 or Azure blob, and loading of that vector data into search engines like Marqo, Qdrant, ScaNN or NGT for querying. Some companies that require lower latency vector querying may choose to deploy and self-host an open source vector database solution.
If vector database usage continues to grow with the business adoption of AI and LLMs, I think that most business IT orgs will choose to procure a fully-managed vector database solution for the ease of deployment, maintenance, and integration with other tools in the AI tech stack.
I will pick Qdrant as a potential investment given the early stage opportunity it presents and the positive traction and reputation it has gained amongst developers as a viable open source alternative to market leaders such as Pinecone and Weaviate. I think a future Series A investment has the potential for meaningful returns.
I will bet against Zilliz as an investment at its current stage. I think that Zilliz offers one of the most comprehensive vector storage and search capabilities, and best query performance amongst market leaders. However, I think they will face adoption resistance in Western nations given that it is a Chinese company. Additionally, Zilliz faces a hard monetization path in China, where SMEs are very cost-sensitive and prefer to develop more technology in-house compared to Western companies.